
v0.7 Release Highlights
v0.7 brings improvements on the low-level system infrastructure as well as on the high-level user-facing utilities. Many of them involve contributions from the user community. We are grateful to see such a growing trend and welcome more in the future. Here are the notable updates.
GPU-based Neighbor Sampling
We worked with NVIDIA to make DGL support uniform neighbor sampling and MFG conversion on GPU. This removes the need to move samples from CPU to GPU in each iteration and at the same time accelerate the sampling step using GPU acceleration. As a result, experiment for GraphSAGE on the ogbn-product graph gets a >10x speedup (reduced from 113s to 11s per epoch) on a g3.16x instance. To enable the feature, create a NodeDataLoader with a GPU graph and specify the sampling device to be on GPU:
g = ... # create a graph
g = g.to('cuda:0') # move the graph to GPU
# create a data loader
dataloader = dgl.dataloading.NodeDataLoader(
g, # now accepts graph on GPU
train_nid,
sampler,
device=torch.device('cuda:0'), # specify the sampling device
num_workers=0, # num_workers must be 0
batch_size=1000,
drop_last=False,
shuffle=True)
# training loop
for input_nodes, output_nodes, sample_graphs in dataloader:
# the produced sample_graphs are already on GPU
train_on(input_nodes, output_nodes, sample_graphs)
The following docs have been updated accordingly:
- A new user guide chapter Using GPU for Neighborhood Sampling about when and how to use this new feature.
- The API doc of NodeDataLoader.
We thank @nv-dlasalle from NVIDIA for contributing the CUDA kernels for performing neighbor sampling as well as MFG conversion.
Improved CPU Message Passing Kernel
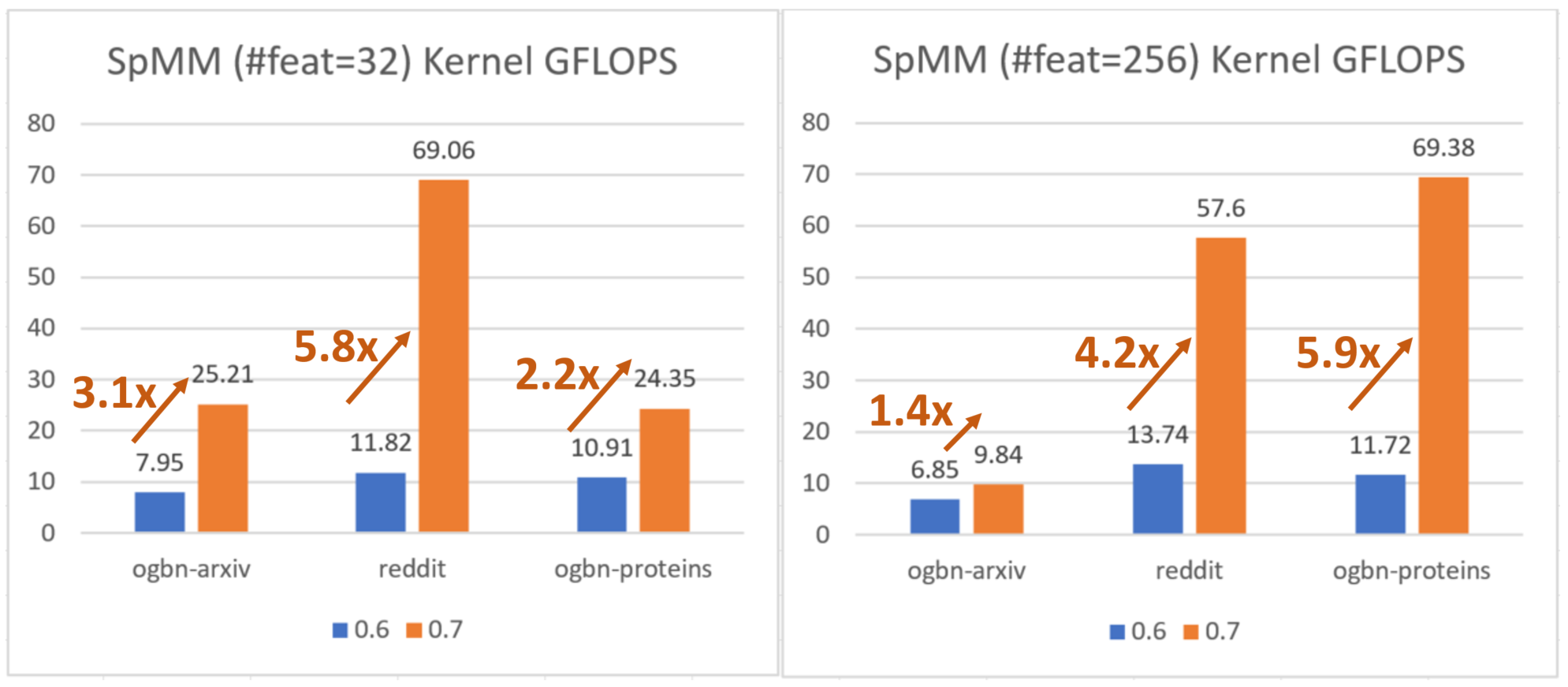
The core SpMM kernel for GNN message passing on CPU has been re-implemented. The new kernel performs tiling on CSR matrix and leverages Intel’s LibXSMM for kernel generation. Please read the paper https://arxiv.org/abs/2104.06700 for more details. The feature is turned on automatically for Xeon CPUs which shows significant speed boost. We thank @sanchit-misra and Intel for contributing the new CPU kernel.
Better NodeEmbedding for multi-GPU training and distributed training
DGL now utilizes NCCL to synchronize the
gradients of sparse node embeddings (dgl.nn.NodeEmbedding) during training. It
is enabled automatically when users specify nccl as the backend for
torch.distributed.init_process_group. Our experiment shows a 20% speedup
(reduced from 47.2s to 39.5s per epoch) on a g4dn.12xlarge (4 T4 GPU) instance
for training RGCN on ogbn-mag graph. We thank the effort from @nv-dlasalle and
NVIDIA. Distributed node embedding now uses synchronized gradient update,
making the training more stable.
DGL Kubernetes Operator
Qihoo360 built a DGL Operator that makes running graph neural network distributed or non-distributed training on Kubernetes. Please check out their repository for usage: https://github.com/Qihoo360/dgl-operator.
Other Performance Gains
Apart from the major feature improvement, we have also received helps from community contributors for fixing performance issues. Notably, DGL’s CPU random walk sampling is improved by 24x on medium to large size graphs; the memory consumption of distributed training set splitting drops by ~7x on graphs of billion scale.
More than More Models
As usual, the release brings a batch of 19 new model examples to the repository bringing the total number to be over 90. To help users find examples that fit their needs (e.g. certain topic, datasets), we present a new search tool on dgl.ai which supports finding examples by keywords.
Below are the new models added in v0.7.
- Interaction Networks for Learning about Objects, Relations, and Physics
- Multi-GPU RGAT for OGB-LSC Node Classification
- Network Embedding with Completely-imbalanced Labels
- Temporal Graph Networks improved
- Diffusion Convolutional Recurrent Neural Network
- Gated Attention Networks for Learning on Large and Spatiotemporal Graphs
- DeeperGCN
- Deep Graph Contrastive Representation Learning
- Graph Neural Networks Inspired by Classical Iterative Algorithms
- GraphSAINT
- Label Propagation
- Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
- GCNII
- Latent Dirichlet Allocation on GPU
- A Heterogeneous Information Network based Cross Domain Insurance Recommendation System for Cold Start Users
- Five heterogeneous graph models: HetGNN/GTN/HAN/NSHE/MAGNN. Sparse matrix multiplication and addition with autograd are also added as a result.
- Heterogeneous Graph Attention Networks with minibatch sampling
- Learning Hierarchical Graph Neural Networks for Image Clustering
Tutorials for Multi-GPU and Distributed Training
With a growing interest in applying GNNs on large-scale graphs, we see many questions from our users about how to utilize multi-GPU or multi-machine for acceleration. In this release, we published two new tutorials about multi-GPU training for node classification and graph classification, respectively. There is also a new tutorial about distributed training across multiple machines. All of them are available at docs.dgl.ai.
Further Readings
- Full release note: https://github.com/dmlc/dgl/releases/tag/v0.7.0
26 July