
DGL 2.1: GPU Acceleration for Your GNN Data Pipeline
We are happy to announce the release of DGL 2.1. In this release, we are making GNN data loading lightning fast. We introduce GPU acceleration for the whole GNN data loading pipeline in GraphBolt, including the graph sampling and feature fetching stages.
Flexible data pipeline & customizable stages, all accelerated on your GPU
Starting from this release, the data moving stage can now be moved earlier in the data pipeline to enable GPU acceleration. With this in mind, the following permutations of the core stages are now possible:
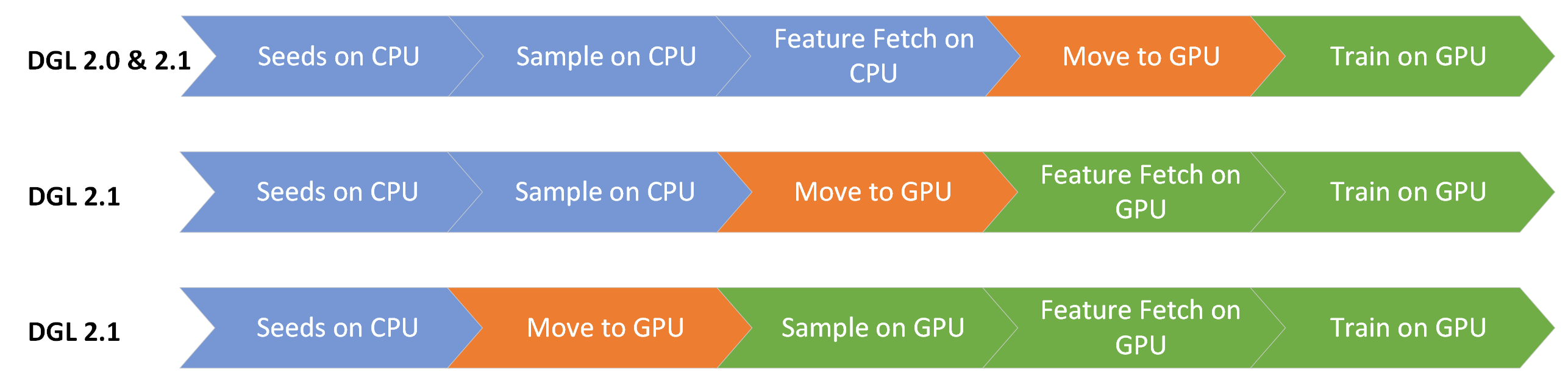
To execute all of the data loading stages on the GPU, the graph and the features need to be GPU accessible. As the GPU memory may be limited, GraphBolt offers an in-place pinning operation to enable GPU access to the graph and features resident in main memory.
# Pin the graph and features in-place.
graph = dataset.graph.pin_memory_()
features = dataset.feature.pin_memory_()
However, if GPU has sufficient memory, either graph and/or its features can be moved to the GPU as follows:
# Move the graph and features to the GPU.
graph = dataset.graph.to("cuda:0")
features = dataset.feature.to("cuda:0")
It may be the case that the GPU has a large memory, however it may not be large enough to fit all the features. In that case, it is possible to cache some part of the features using gb.GPUCachedFeature, please see the GraphBolt multiGPU example.
By placing the copy operation earlier in the pipeline enables GPU execution for the rest of the operations. All of the GraphBolt components compose as you expect.
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Copy here to execute the remaining operations on the GPU.
dp = dp.copy_to(device="cuda:0")
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
The descriptive nature of the PyTorch datapipe lets us take a defined data
pipeline, make modifications to it to support GPU specific optimizations with no
change to the user experience. Two such examples are the overlap_feature_fetch
and overlap_graph_fetch arguments of gb.DataLoader,
where the feature fetching and graph access operations are overlapped with the
rest of the operations using a separate CUDA stream via pipeline parallelism.
GPU acceleration speedups
The dgl.graphbolt doesn’t just give you flexibility, it also provides top performance under the hood. As for the 2.1 release, almost all dgl.graphbolt operations are GPU accelerated, except for sampling with replacement. Additionally, the feature fetch operation now runs in parallel with everything else, via pipeline parallelism. This has the potential to cut runtimes by up to 2x depending on the scenario. Moreover, utilizing gb.GPUCachedFeature can cut feature transfer times even more, our multi-GPU benchmarks show up to 1.6x speedup.
To evaluate the performance of GraphBolt, we have tested 4 different scenarios:
- Single-GPU Node Classification
- Single-GPU Link Prediction
- Single-GPU Heterogeneous Node Classification
- Multi-GPU Node Classification
In these scenarios, we will compare 5 different configurations. First two are the existing baselines, and the last three are new configurations enabled by the DGL 2.1 release:
- GraphBolt CPU backend, denoted as “dgl.graphbolt (cpu)”.
- The legacy DGL dataloader with UVA on GPU, denoted as “Legacy DGL (pinned)” by pinning the dataset in system memory.
- GraphBolt GPU backend, denoted as “dgl.graphbolt (pinned)” by pinning the dataset in system memory.
- GraphBolt GPU backend, denoted as “dgl.graphbolt (pinned, 5M)” by pinning the dataset in system memory, utilizing gb.GPUCachedFeature to cache 5M of the node features.
- GraphBolt GPU backend, denoted as “dgl.graphbolt (cuda)” by moving the dataset to the GPU memory.
All the experiments were run on an NVIDIA DGX-A100 system with 8 GPUs.
Single-GPU Node Classification
We evaluate the performance of GraphBolt and the Legacy DGL dataloader when the dataset is stored in pinned memory (UVA) against the CPU GraphBolt baseline. We use a 3 layer GraphSage model with batch size 1024 and fanout 10 in each layer and evaluate the performance on the ogbn-products and ogbn-papers100M datasets using the listed baselines above.
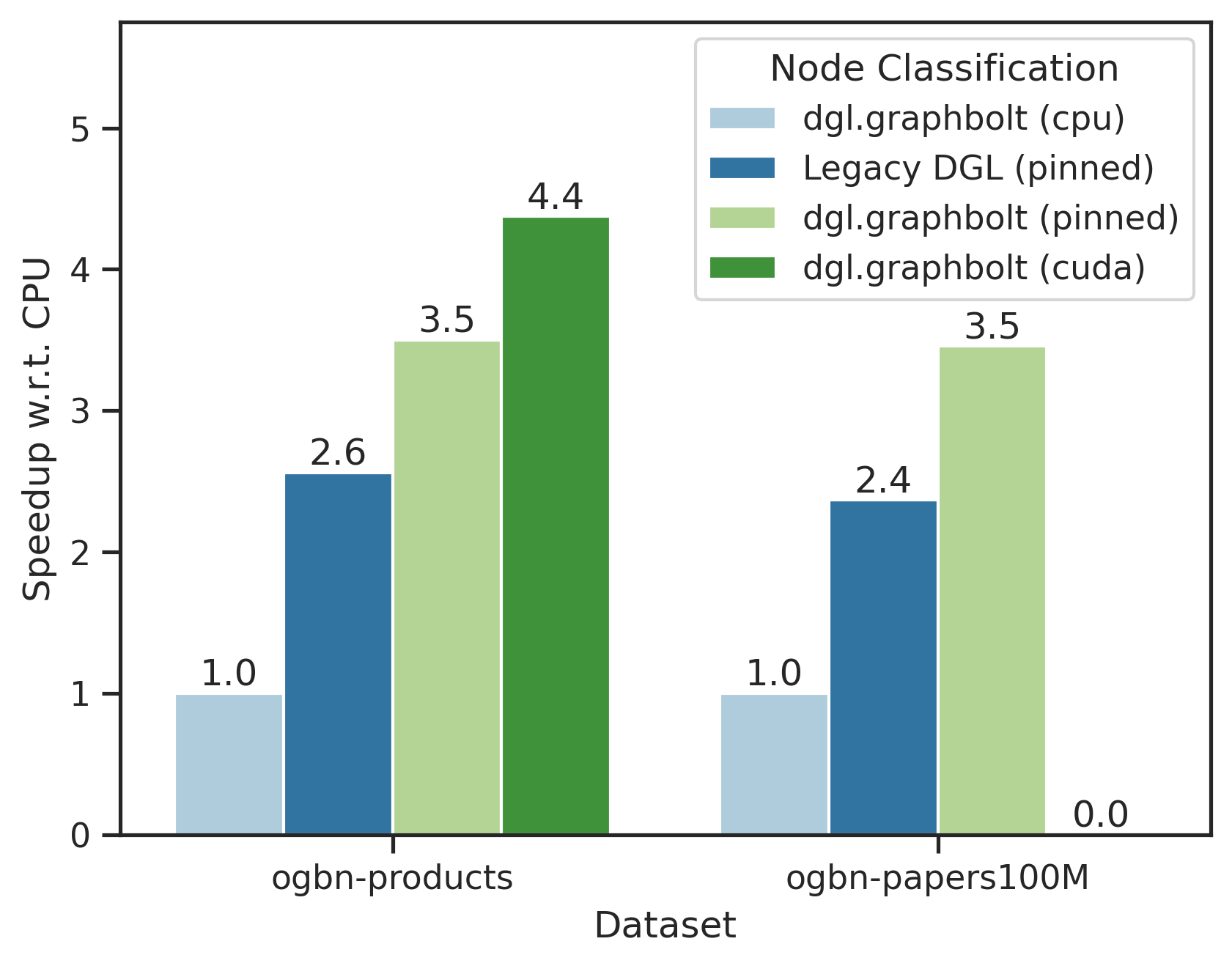
As one can see, GraphBolt’s new GPU backend can get up to 4.2x speedup compared to the GraphBolt CPU baseline while the legacy DGL dataloader can get at most 2.5x.
Single-GPU Link Prediction
Here, we shift our focus to the link prediction scenario on the ogbl-citation2 dataset with a similar setting as the previous section. Here, two different modes are evaluated, including or excluding reverse edges.
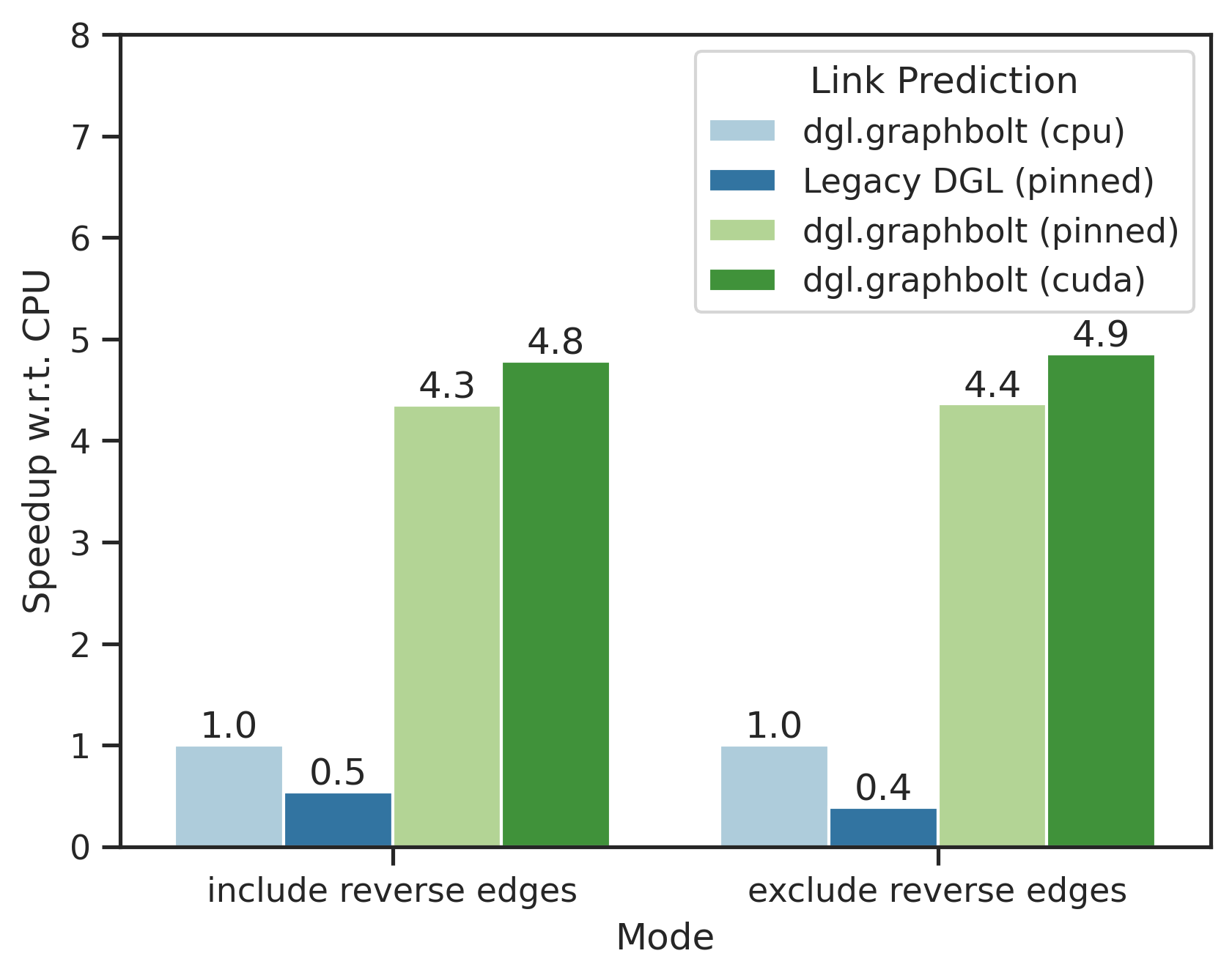
We observe that GraphBolt’s new GPU backend can get up to 5x speedup compared to its CPU baselines. Legacy DGL dataloader is slow due to missing GPU counterparts of some operations required for link prediction dataloading.
Single-GPU Heterogeneous Node Classification
You can accelerate heterogeneous sampling on your GPU as well. The R-GCN example runtime on the ogbn-mag dataset was 43.5s with the “dgl.graphbolt (cpu)” baseline and it went down to 25.2s with the new “dgl.graphbolt (pinned)” for a 1.73x speedup. You can expect the speedup numbers to increase as we optimize the different use cases for the GPU.
Multi-GPU Node Classification
Here, we evaluate the node classification use case in the multi-GPU setting with GraphSage model on the ogbn-papers100M dataset (111M nodes and 3.2B edges). A similar setting is used as the single-GPU scenario except that each GPU is using a batch size of 1024 with global batch size increasing linearly with the number of GPUs.
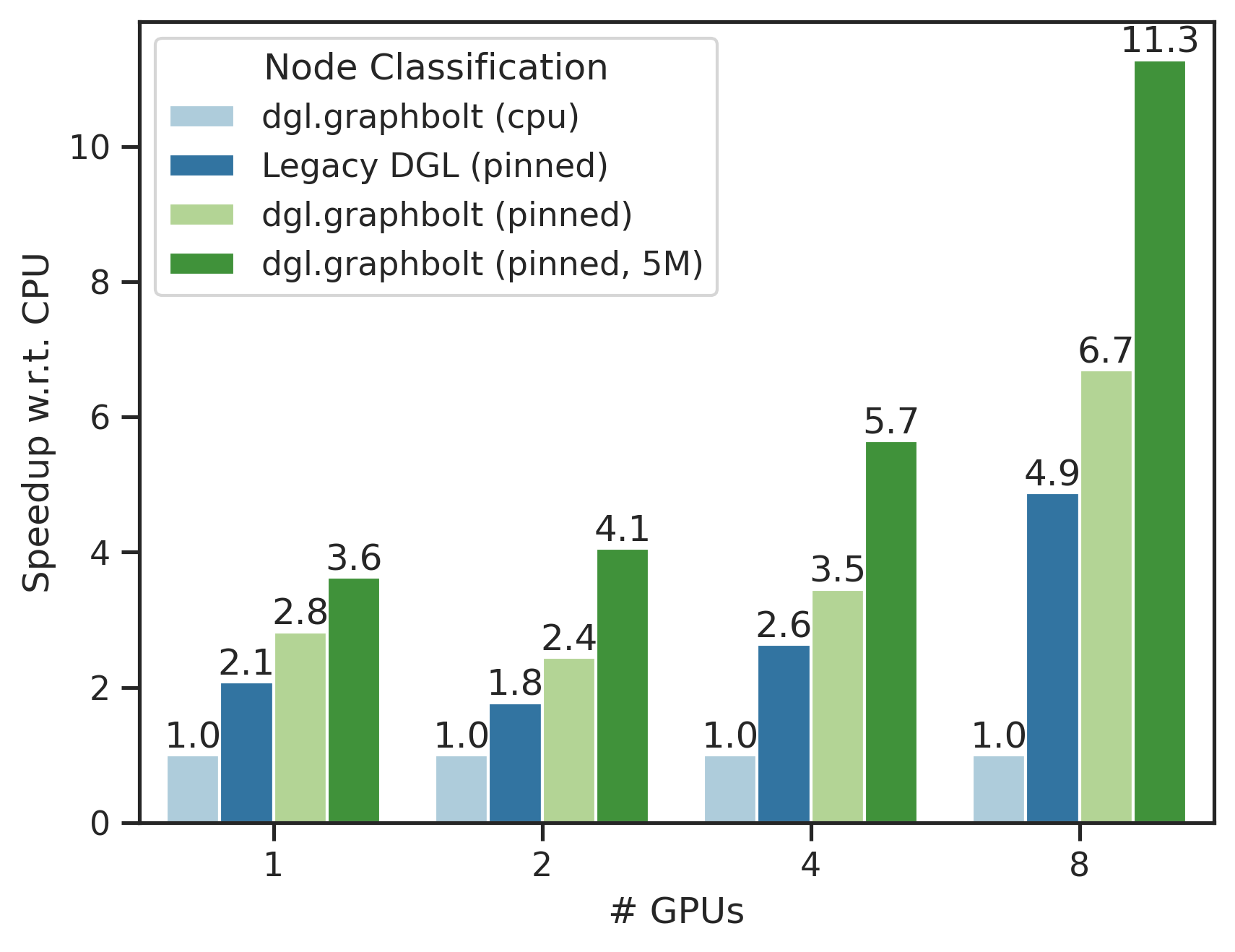
40GB memory on each of our A100 GPUs can be utilized by the GPU cache feature in GraphBolt. We can achieve 1.75x improvement on a single GPU and 2.31x improvement on 8 GPUs compared to previous state-of-the-art baseline, Legacy DGL (pinned). Moreover, compared to the GraphBolt CPU baseline, we achieve over 10x improvement.
Reduced graph storage space requirements
Many large-scale graphs and existing GNN datasets have fewer than 2 billion nodes but more than 2 billion edges. One such example is the ogbn-papers100M graph with its 111 million nodes and 3.2 billion edges. dgl.graphbolt uses the CSC (Compressed Sparse Column) format to store your graph in a memory efficient way. With our latest additions, the memory usage now scales by 4 bytes (int32) w.r.t. # edges and 8 bytes (int64) w.r.t. # nodes, meaning close to 2x space savings for graph storage by using mixed data types. The provided preprocessing functionality casts the tensors in your dataset into the smallest data types automatically for optimum space use and performance such as the edge type information in the heterogeneous case. With these optimizations, you get 3x space savings for the heterogenous ogb-lsc-mag240m graph compared to our previous release.
What’s more
Furthermore, dgl.graphbolt is compatible with Pytorch Geometric as well. In the figure below, the notation in the parentheses represents where the graph and the features are placed. “(cpu-cuda)” means that the graph is placed on the CPU while the features are moved to the GPU. We compare our advanced PyG example against the PyG official example, both using the PyG GraphSAGE model. We run the Node Classification task on the ogbn-products dataset with [15, 10, 5] fanout.
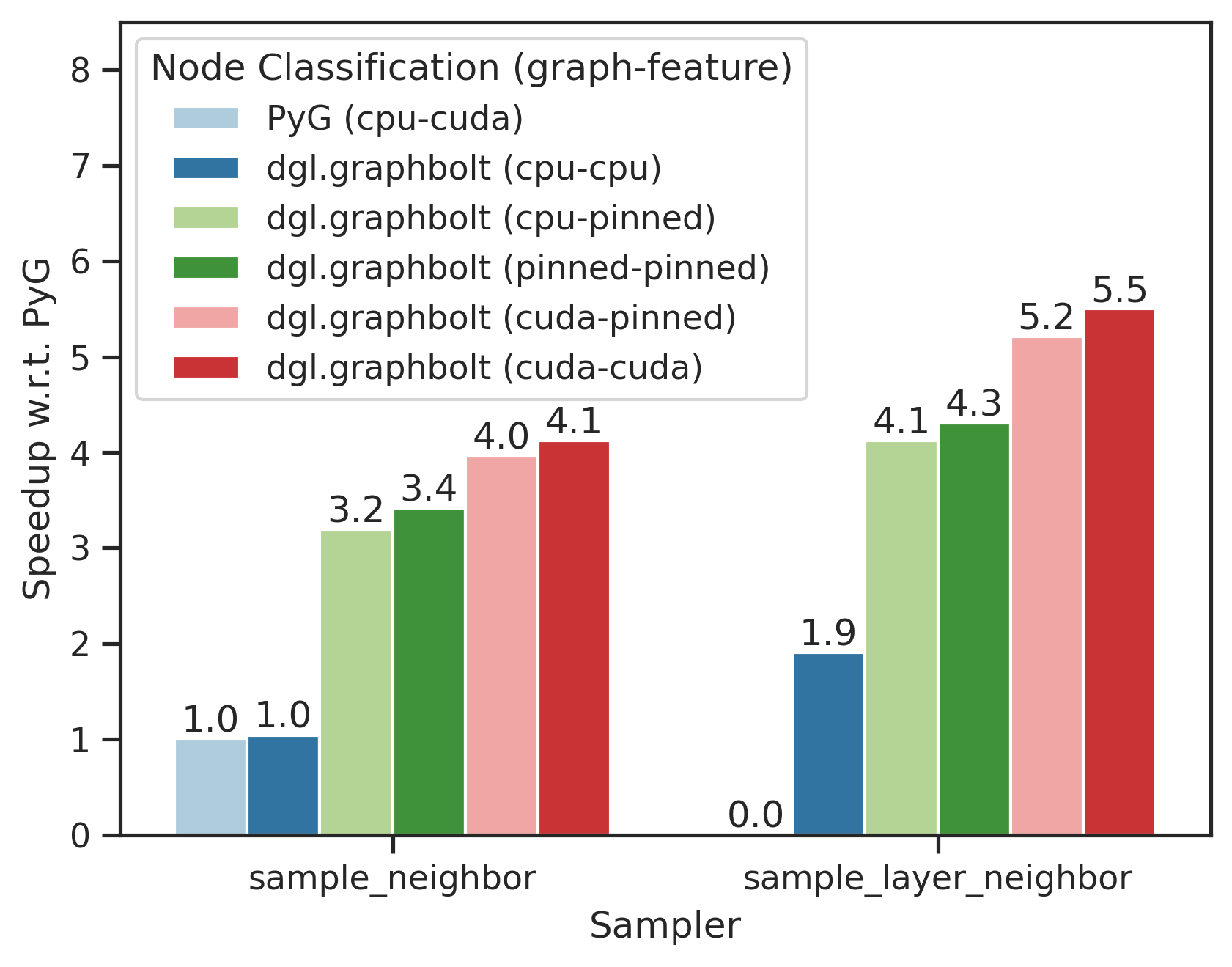
While providing an extremely optimized Neighbor Sampler implementation, we also offer a new drop-in replacement called Layer Neighbor Sampler from NeurIPS 2023. One can see that we provide up to 5.5x speedup over PyG, combining GPU acceleration, pipeline parallelism and the state-of-the-art algorithms. For more information on the new features in DGL 2.1, please refer to our release notes.
Get started with DGL 2.1
You can easily install DGL 2.1 with dgl.graphbolt on any platform using pip or conda. Dive into our updated Stochastic Training of GNNs with GraphBolt tutorial and experiment with our node classification and link prediction examples in Google Colab. No need to set up a local environment - just point and click! We also updated the existing 7 comprehensive single-GPU examples and 1 multi-GPU example with GPU Acceleration options. DGL 2.1 will be featured in the NVIDIA DGL container 24.03 release which will be released before the end of March 2024.
We welcome your feedback and are available via Github issues and Discuss posts. Join our Slack channel to stay updated and to connect with the community.
06 March
By Muhammed Fatih Balin, in release