
DGL 2.0: Streamlining Your GNN Data Pipeline from Bottleneck to Boost
We’re thrilled to announce the release of DGL 2.0, a major milestone in our mission to empower developers with cutting-edge tools for Graph Neural Networks (GNNs). Traditionally, data loading has been a significant bottleneck in GNN training. Complex graph structures and the need for efficient sampling often lead to slow data loading times and resource constraints. This can drastically hinder the training speed and scalability of your GNN models. DGL 2.0 breaks free from these limitations with the introduction of dgl.graphbolt, a revolutionary data loading framework that supercharges your GNN training by streamlining the data pipeline.
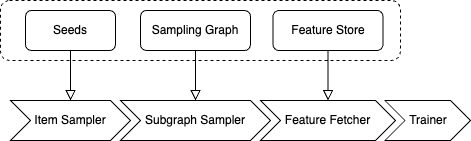
Flexible data pipeline & customizable stages
One size doesn’t fit all - and especially not when it comes to dealing with a variety of graph data and GNN tasks. For instance, link prediction requires negative sampling but not node classification, some features are too large to be stored in memory, and occasionally, we might combine multiple sampling operations to form subgraphs. To offer adaptable operators while maintaining high performance, dgl.graphbolt integrates seamlessly with the PyTorch datapipe, relying on the unified “MiniBatch” data structure to connect processing stages. The core stages are defined as:
- Item Sampling: randomly selects a subset (nodes, edges, graphs) from the entire training set as an initial mini-batch for downstream computation.
- Negative Sampling (for Link Prediction): generates non-existing edges as negative examples.
- Subgraph Sampling: generates subgraphs based on the input nodes/edges.
- Feature Fetching: fetches related node/edge features from the dataset for the given input.
- Data Moving (for training on GPU): moves the data to specified device for training.
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
# Copy to GPU for training.
dp = dp.copy_to(device="cuda:0")
The dgl.graphbolt allows you to plug in your own custom processing steps to build the perfect data pipeline for your needs, for example:
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Exclude seed edges.
dp = dp.transform(gb.exclude_seed_edges)
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
# Copy to GPU for training.
dp = dp.copy_to(device="cuda:0")
The dgl.graphbolt empowers you to customize stages in your data pipelines. Implement custom stages using pre-defined APIs, such as loading features from external storage or adding customized caching mechanisms (e.g. GPUCachedFeature), and integrate the custom stages seamlessly without any modifications to your core training code.
Speed enhancement & memory efficiency
The dgl.graphbolt doesn’t just give you flexibility, it also provides top performance under the hood. It features a compact graph data structure for efficient sampling, blazing-fast multi-threaded neighbor sampling operator and edge exclusion operator, and a built-in option to store large feature tensors outside your CPU’s main memory. Additionally, The dgl.graphbolt takes care of scheduling across all hardware, minimizing wait times and maximizing efficiency.
The dgl.graphbolt brings impressive speed gains to your GNN training, showcasing over 30% faster node classification in our benchmark and a remarkable ~390% acceleration for link prediction in our benchmark that involve edge exclusion.
| Epoch Time(s) | GraphSAGE | R-GCN |
|---|---|---|
| DGL Dataloader | 22.5 | 73.6 |
| dgl.graphbolt | 17.2 | 64.6 |
| **Speedup** | **1.31x** | **1.14x** |
| Epoch Time(s) | include seeds | exclude seeds |
|---|---|---|
| DGL Dataloader | 37.75 | 135.32 |
| dgl.graphbolt | 15.51 | 27.62 |
| **Speedup** | **2.43x** | **4.90x** |
For memory-constrained training on enormous graphs like OGBN-MAG240m, the dgl.graphbolt also proves its worth. While both utilize mmap-based optimization, compared to DGL dataloader, the dgl.graphbolt boasts a substantial speedup. The dgl.graphbolt’s well-defined component API streamlines the process for contributors to refine out-of-core RAM solutions for future optimization, ensuring even the most massive graphs can be tackled with ease.
| Iteration time with different RAM size (s) | 128GB RAM | 256GB RAM | 384GB RAM |
|---|---|---|---|
| Naïve DGL dataloader | OOM | OOM | OOM |
| Optimized DGL dataloader | 65.42 | 3.86 | 0.30 |
| dgl.graphbolt | 60.99 | 3.21 | 0.23 |
What’s more
Furthermore, DGL 2.0 includes various new additions such as a hetero-relational GCN example and several datasets. Improvements have been introduced to the system, examples, and documentation, including updates to the CPU Docker tcmalloc, supporting sparse matrix slicing operators and enhancements in various examples. A set of utilities for building graph transformer models is released along with this version, including NN modules such as positional encoders and layers as building blocks, and examples and tutorials demonstrating the usage of them. Additionally, numerous bug fixes have been implemented, resolving issues such as the cusparseCreateCsr format for cuda12, addressing the lazy device copy problem related to DGL node/edge features e.t.c. For more information on the new additions and changes in DGL 2.0, please refer to our release note.
Get started with DGL 2.0
You can easily install DGL 2.0 with dgl.graphbolt on any platform using pip or conda. To jump right in, dive into our brand-new Stochastic Training of GNNs with GraphBolt tutorial and experiment with our node classification and link prediction examples in Google Colab. No need to set up a local environment - just point and click! This first release of DGL 2.0 with dgl.graphbolt packs a punch with 7 comprehensive single-GPU examples and 1 multi-GPU example, covering a wide range of tasks.
We welcome your feedback and are available via Github issues and Discuss posts. Join our Slack channel to stay updated and to connect with the community.
26 January