
v0.6 Release Highlight
The recent DGL 0.6 release is a major update on many aspects of the project including documentation, APIs, system speed, and scalability. This article highlights some of the new features and enhancements.
A Blitz Introduction to DGL in 120 minutes
The brand new set of tutorials come from our past hands-on tutorials in several major academic conferences (e.g., KDD’19, KDD’20, WWW’20). They start from an end-to-end example of using GNNs for node classification, and gradually unveil the core components in DGL such as DGLGraph, GNN modules, and graph datasets. The tutorials are now available on docs.dgl.ai.
A Gentle Tutorial on Mini-batch Training of GNNs
The scale of real world data can be massive, which demands training GNNs stochastically by mini-batches. However, unlike images or text corpus where data samples are independent, stochastic training of GNNs is more complex because one must handle the dependencies among samples. We observed that stochastic training is one of the most-asked topics on our discuss forum. In 0.6, we summarize the answers to those common questions in a set of tutorials on stochastic training of GNNs, including the insight into neighbor sampling algorithms, training loops and code snippets in DGL to realize them.
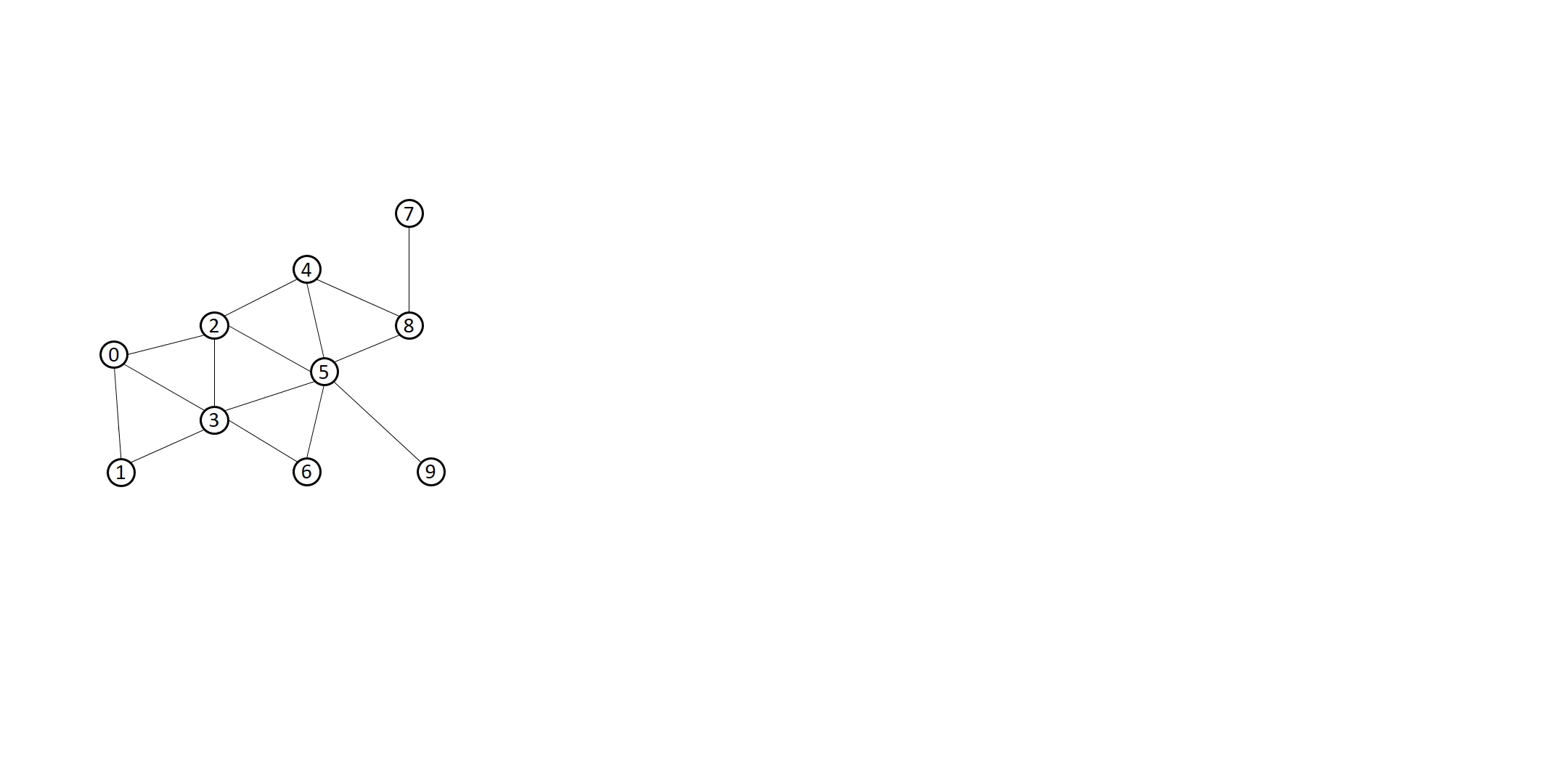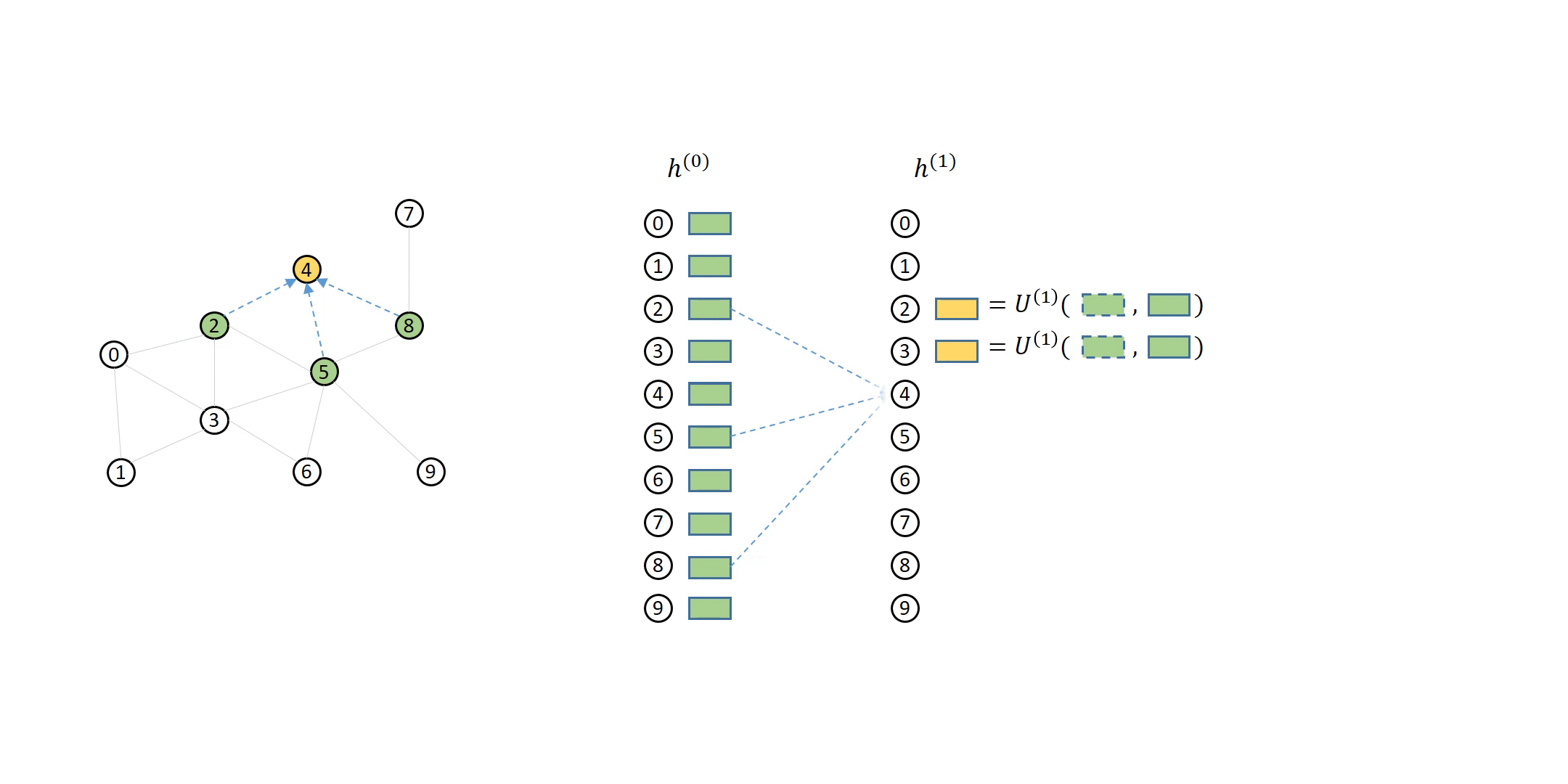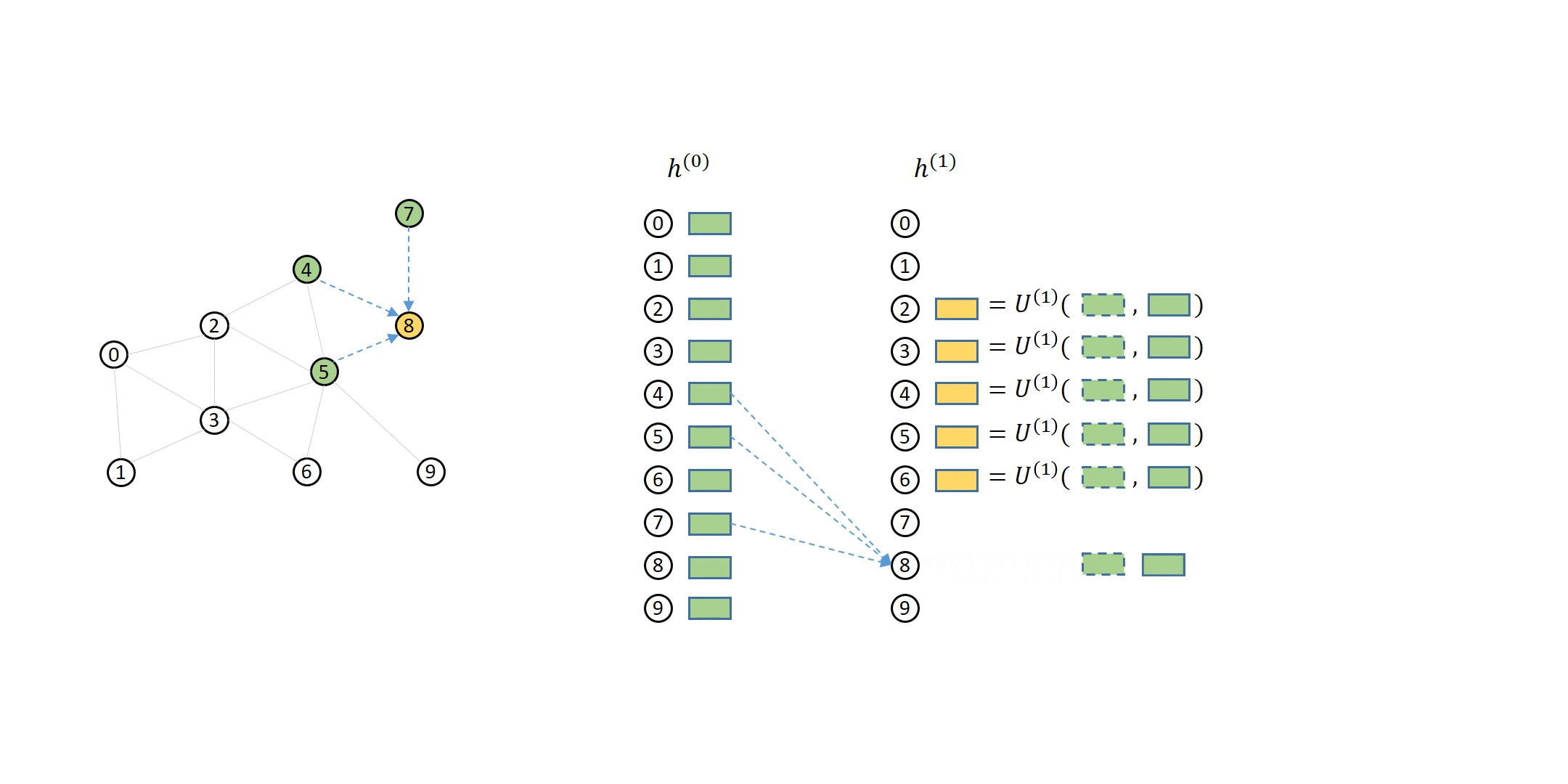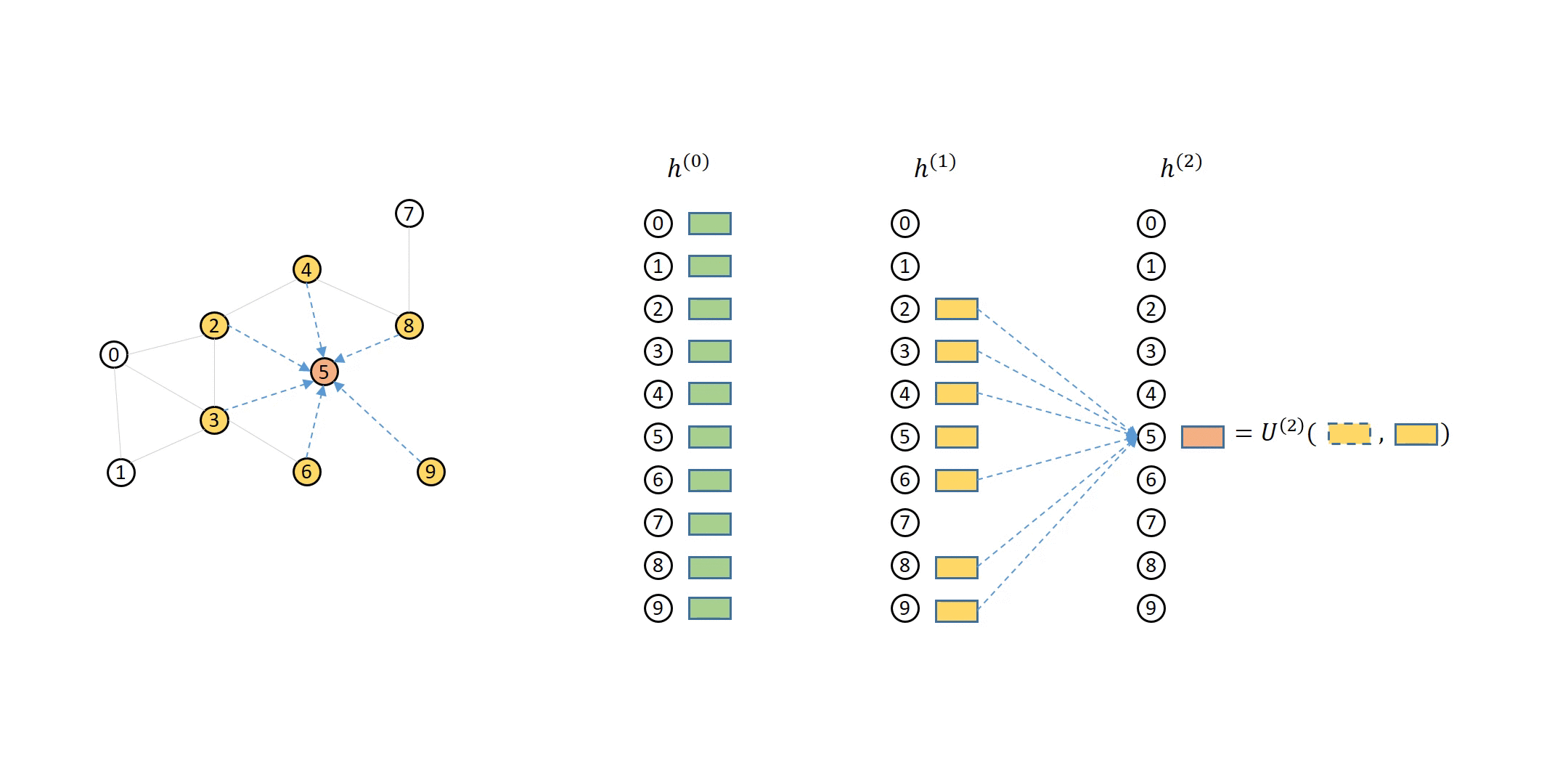
More Examples
The release includes 13 new examples, brings a total of 72 models:
- MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing: https://github.com/dmlc/dgl/tree/master/examples/pytorch/mixhop
- Self-Attention Graph Pooling: https://github.com/dmlc/dgl/tree/master/examples/pytorch/sagpool
- GNN-FiLM: Graph Neural Networks with Feature-wise Linear Modulation: https://github.com/dmlc/dgl/tree/master/examples/pytorch/GNN-FiLM
- TensorFlow implementation of Simplifying Graph Convolutional Networks: https://github.com/dmlc/dgl/tree/master/examples/tensorflow/sgc
- Graph Representation Learning via Hard and Channel-Wise Attention Networks: https://github.com/dmlc/dgl/tree/master/examples/pytorch/hardgat
- Graph Random Neural Network for Semi-Supervised Learning on Graphs: https://github.com/dmlc/dgl/tree/master/examples/pytorch/grand
- Hierarchical Graph Pooling with Structure Learning: https://github.com/dmlc/dgl/tree/master/examples/pytorch/hgp_sl
- Towards Deeper Graph Neural Networks: https://github.com/dmlc/dgl/tree/master/examples/pytorch/dagnn
- PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation/PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (part segmentation): https://github.com/dmlc/dgl/tree/master/examples/pytorch/pointcloud/pointnet
- Graph Cross Networks with Vertex Infomax Pooling: https://github.com/dmlc/dgl/tree/master/examples/pytorch/gxn
- Neural Graph Collaborative Filtering: https://github.com/dmlc/dgl/tree/master/examples/pytorch/NGCF
- Link Prediction Based on Graph Neural Networks: https://github.com/dmlc/dgl/tree/master/examples/pytorch/seal
- Graph Neural Networks with Convolutional ARMA Filters: https://github.com/dmlc/dgl/tree/master/examples/pytorch/arma
The official example folder now indexes the examples by their notable tags such as their targeted tasks and so on.
Usability Enhancements
- Two new APIs
DGLGraph.set_batch_num_nodesandDGLGraph.set_batch_num_edgesfor setting batch information manually, which are useful for transforming a batched graph into another or constructing a new batched graph manually. - A new API
GraphDataLoader, a data loader wrapper for graph classification tasks. - A new dataset class
QM9Dataset. - A new namespace
dgl.nn.functionalfor hosting NN related utility functions. - DGL now supports training with half precision and is compatible with PyTorch’s automatic mixed precision package. See the user guide chapter for how to use it.
- (Experimental) Users can now use DistGraph with heterogeneous graph data. This also applies to
dgl.sample_neighborson DistGraph. In addition, DGL supports distributed graph partitioning on a cluster of machines. See the user guide chapter for more details. - (Experimental) Several new APIs for training sparse embeddings:
dgl.nn.NodeEmbeddingis a dedicated class for storing trainable node embeddings that can scale to graphs with millions of nodes.dgl.optim.SparseAdagradanddgl.optim.SparseAdamare two optimizers for the NodeEmbedding class.
System Efficiency Improvements
- With PyTorch backend, DGL will use PyTorch’s native memory management to cache repeated memory allocation and deallocation.
- A new implementation for
nn.RelGraphConvwhenlow_mem=True(PyTorch backend). A benchmark on V100 GPU shows it gives a 4.8x boost in training speed on AIFB dataset. - Faster CPU kernels using AVX512 instructions.
- Faster GPU kernels on CUDA 11.
Further Readings
- Full release note: https://github.com/dmlc/dgl/releases/tag/v0.6.0
25 February