Node Classification
This tutorial shows how to train a multi-layer GraphSAGE for node classification on ogbn-arxiv provided by Open Graph Benchmark (OGB). The dataset contains around 170 thousand nodes and 1 million edges.
![]()
By the end of this tutorial, you will be able to
Train a GNN model for node classification on a single GPU with DGL’s neighbor sampling components.
Install DGL package
[1]:
# Install required packages.
import os
import torch
import numpy as np
os.environ['TORCH'] = torch.__version__
os.environ['DGLBACKEND'] = "pytorch"
# Install the CPU version in default. If you want to install CUDA version,
# please refer to https://www.dgl.ai/pages/start.html and change runtime type
# accordingly.
device = torch.device("cpu")
!pip install --pre dgl -f https://data.dgl.ai/wheels-test/repo.html
try:
import dgl
import dgl.graphbolt as gb
installed = True
except ImportError as error:
installed = False
print(error)
print("DGL installed!" if installed else "DGL not found!")
Looking in links: https://data.dgl.ai/wheels-test/repo.html
Requirement already satisfied: dgl in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (2.2a240410)
Requirement already satisfied: numpy>=1.14.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (1.26.4)
Requirement already satisfied: scipy>=1.1.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (1.14.0)
Requirement already satisfied: networkx>=2.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (3.3)
Requirement already satisfied: requests>=2.19.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (2.32.3)
Requirement already satisfied: tqdm in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (4.66.5)
Requirement already satisfied: psutil>=5.8.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (6.0.0)
Requirement already satisfied: torchdata>=0.5.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (0.7.1)
Requirement already satisfied: pandas in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (2.2.2)
Requirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (3.8)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (2.2.2)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (2024.7.4)
Requirement already satisfied: torch>=2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torchdata>=0.5.0->dgl) (2.4.0+cpu)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2024.1)
Requirement already satisfied: six>=1.5 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas->dgl) (1.16.0)
Requirement already satisfied: filelock in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (3.15.4)
Requirement already satisfied: typing-extensions>=4.8.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (4.12.2)
Requirement already satisfied: sympy in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (1.13.2)
Requirement already satisfied: jinja2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (3.1.4)
Requirement already satisfied: fsspec in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (2024.6.1)
Requirement already satisfied: MarkupSafe>=2.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from jinja2->torch>=2->torchdata>=0.5.0->dgl) (2.1.5)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from sympy->torch>=2->torchdata>=0.5.0->dgl) (1.3.0)
DGL installed!
Loading Dataset
ogbn-arxiv is already prepared as BuiltinDataset in GraphBolt.
[2]:
dataset = gb.BuiltinDataset("ogbn-arxiv").load()
The dataset is already preprocessed.
/home/ubuntu/regression_test/dgl/python/dgl/graphbolt/impl/ondisk_dataset.py:856: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
return torch.load(graph_topology.path)
Dataset consists of graph, feature and tasks. You can get the training-validation-test set from the tasks. Seed nodes and corresponding labels are already stored in each training-validation-test set. Other metadata such as number of classes are also stored in the tasks. In this dataset, there is only one task: node classification.
[3]:
graph = dataset.graph.to(device)
feature = dataset.feature.to(device)
train_set = dataset.tasks[0].train_set
valid_set = dataset.tasks[0].validation_set
test_set = dataset.tasks[0].test_set
task_name = dataset.tasks[0].metadata["name"]
num_classes = dataset.tasks[0].metadata["num_classes"]
print(f"Task: {task_name}. Number of classes: {num_classes}")
Task: node_classification. Number of classes: 40
How DGL Handles Computation Dependency¶
The computation dependency for message passing of a single node can be described as a series of message flow graphs (MFG).
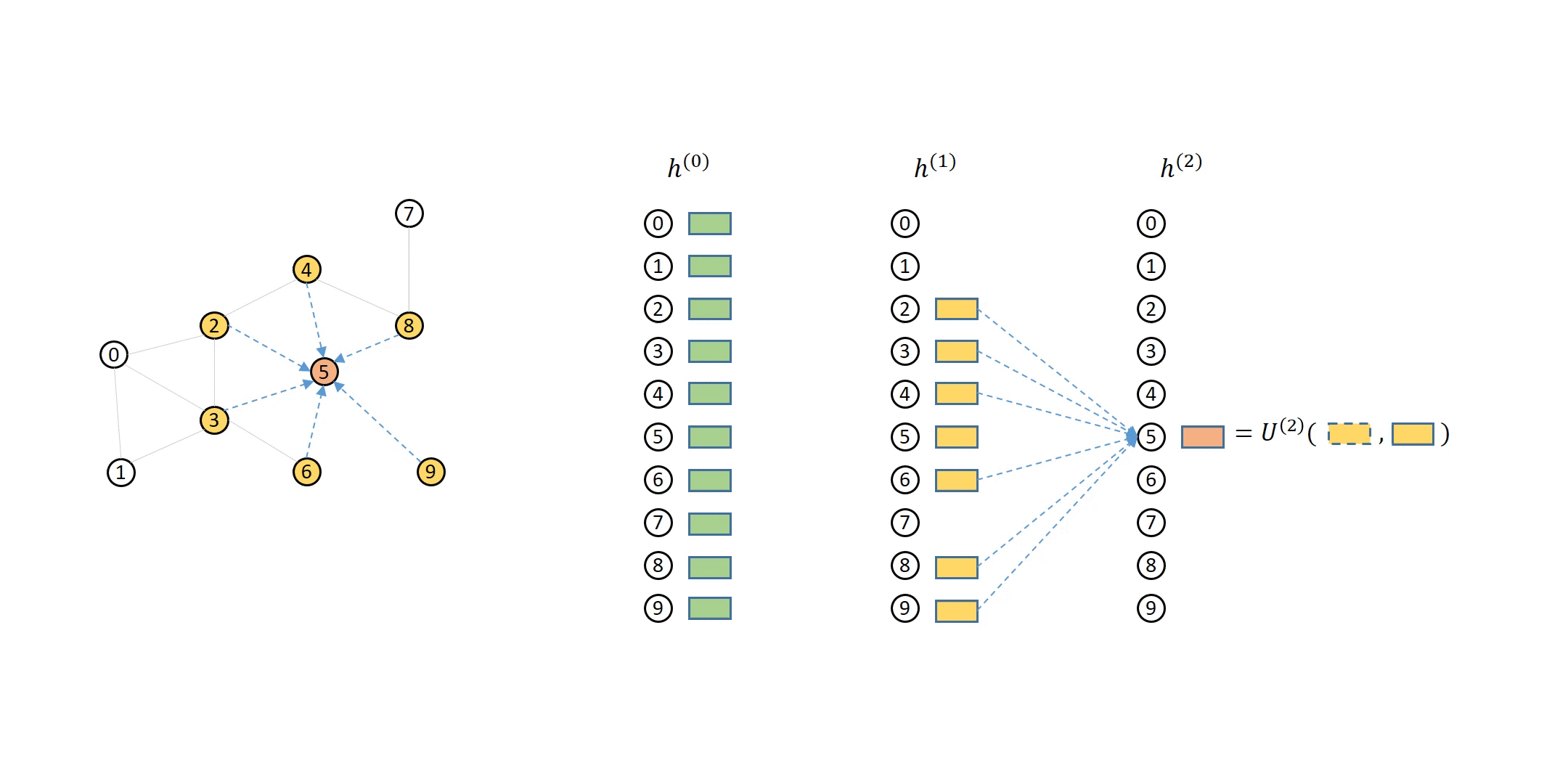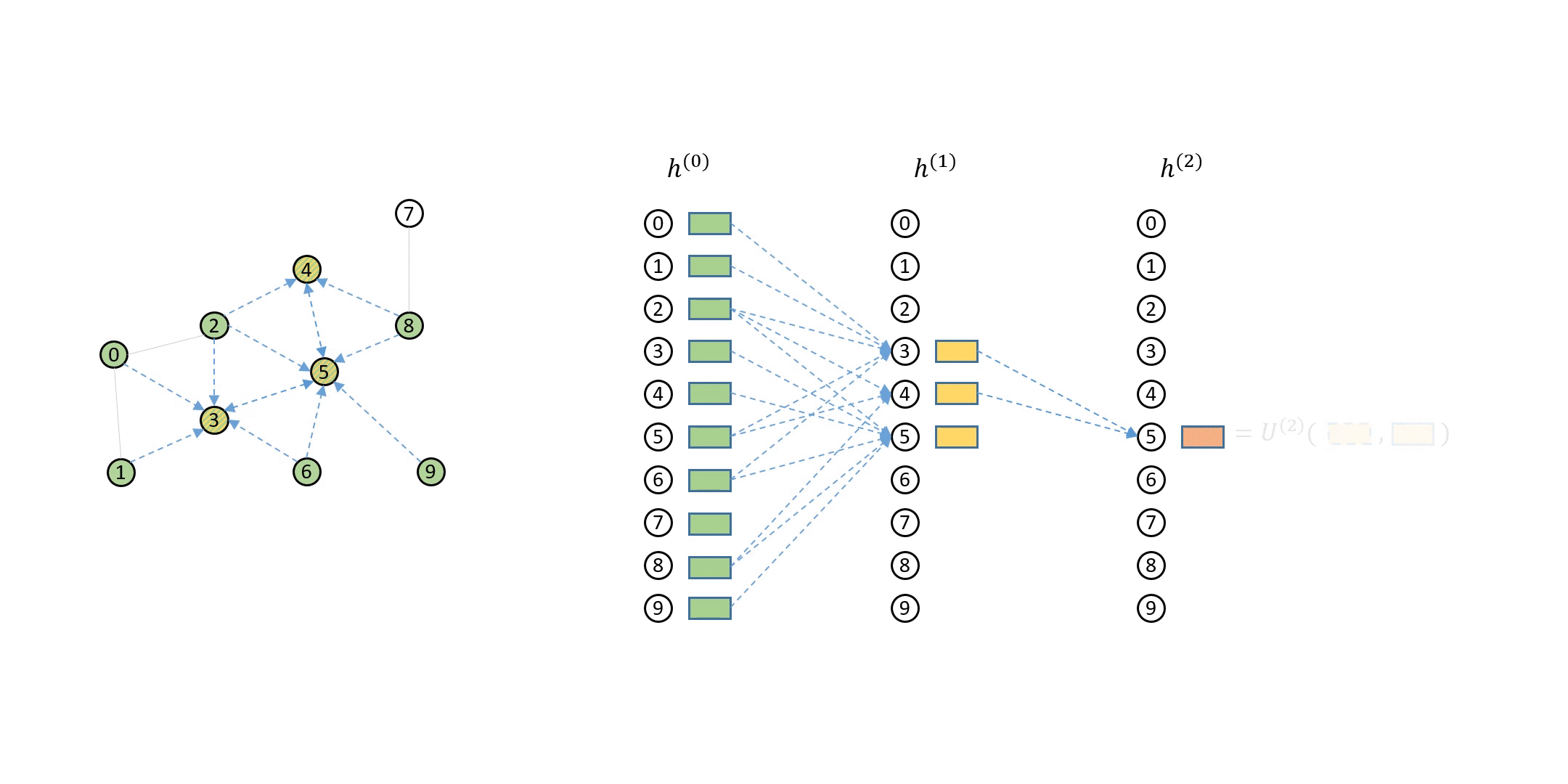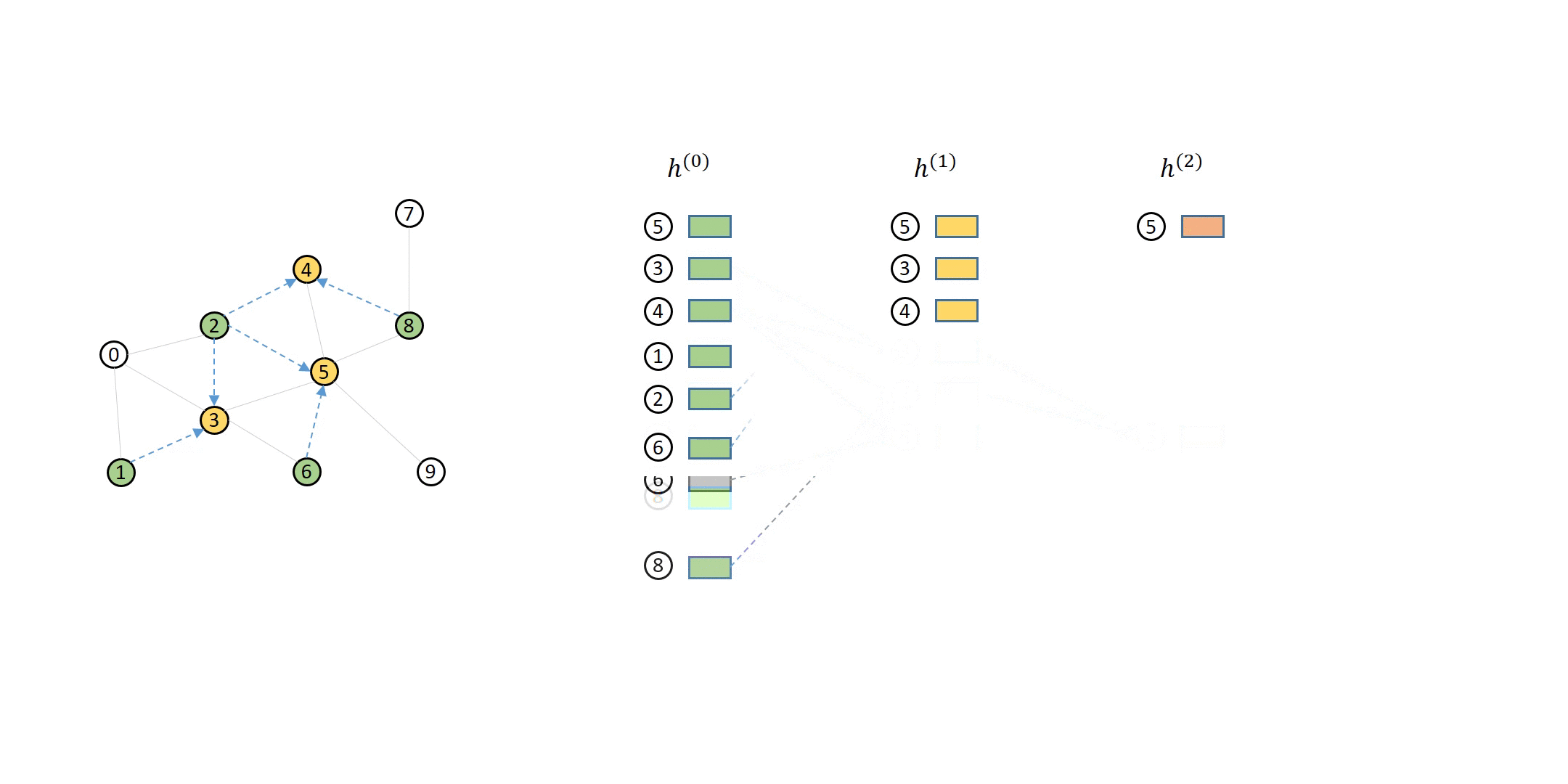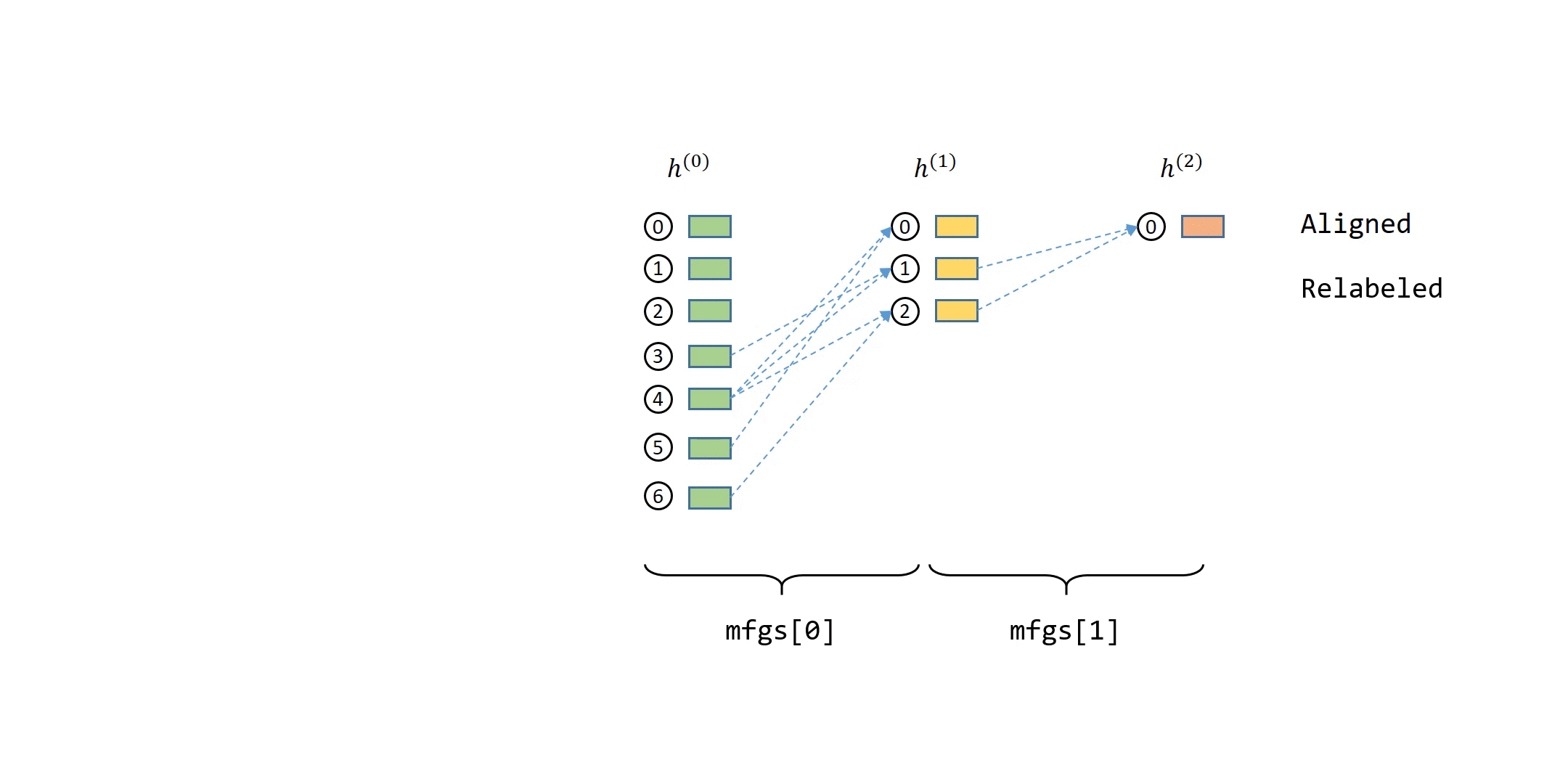
Defining Neighbor Sampler and Data Loader in DGL
DGL provides tools to iterate over the dataset in minibatches while generating the computation dependencies to compute their outputs with the MFGs above. For node classification, you can use dgl.graphbolt.DataLoader for iterating over the dataset. It accepts a data pipe that generates minibatches of nodes and their labels, sample neighbors for each node, and generate the computation dependencies in the form of MFGs. Feature fetching, block creation and copying to target device are also
supported. All these operations are split into separate stages in the data pipe, so that you can customize the data pipeline by inserting your own operations.
Let’s say that each node will gather messages from 4 neighbors on each layer. The code defining the data loader and neighbor sampler will look like the following.
[4]:
def create_dataloader(itemset, shuffle):
datapipe = gb.ItemSampler(itemset, batch_size=1024, shuffle=shuffle)
datapipe = datapipe.copy_to(device, extra_attrs=["seed_nodes"])
datapipe = datapipe.sample_neighbor(graph, [4, 4])
datapipe = datapipe.fetch_feature(feature, node_feature_keys=["feat"])
return gb.DataLoader(datapipe)
You can iterate over the data loader and a MiniBatch object is yielded.
[5]:
data = next(iter(create_dataloader(train_set, shuffle=True)))
print(data)
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[5], line 1
----> 1 data = next(iter(create_dataloader(train_set, shuffle=True)))
2 print(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:630, in _BaseDataLoaderIter.__next__(self)
627 if self._sampler_iter is None:
628 # TODO(https://github.com/pytorch/pytorch/issues/76750)
629 self._reset() # type: ignore[call-arg]
--> 630 data = self._next_data()
631 self._num_yielded += 1
632 if self._dataset_kind == _DatasetKind.Iterable and \
633 self._IterableDataset_len_called is not None and \
634 self._num_yielded > self._IterableDataset_len_called:
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:673, in _SingleProcessDataLoaderIter._next_data(self)
671 def _next_data(self):
672 index = self._next_index() # may raise StopIteration
--> 673 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
674 if self._pin_memory:
675 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:42, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)
40 raise StopIteration
41 else:
---> 42 data = next(self.dataset_iter)
43 return self.collate_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:151, in hook_iterator.<locals>.IteratorDecorator.__next__(self)
149 return self._get_next()
150 else: # Decided against using `contextlib.nullcontext` for performance reasons
--> 151 return self._get_next()
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:139, in hook_iterator.<locals>.IteratorDecorator._get_next(self)
137 """Return next with logic related to iterator validity, profiler, and incrementation of samples yielded."""
138 _check_iterator_valid(self.datapipe, self.iterator_id)
--> 139 result = next(self.iterator)
140 if not self.self_and_has_next_method:
141 self.datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:223, in hook_iterator.<locals>.wrap_next(*args, **kwargs)
221 result = next_func(*args, **kwargs)
222 else:
--> 223 result = next_func(*args, **kwargs)
224 datapipe._number_of_samples_yielded += 1
225 return result
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/datapipe.py:383, in _IterDataPipeSerializationWrapper.__next__(self)
381 def __next__(self) -> T_co: # type: ignore[type-var]
382 assert self._datapipe_iter is not None
--> 383 return next(self._datapipe_iter)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File ~/regression_test/dgl/python/dgl/graphbolt/base.py:263, in EndMarker.__iter__(self)
262 def __iter__(self):
--> 263 yield from self.datapipe
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File ~/regression_test/dgl/python/dgl/graphbolt/dataloader.py:68, in MultiprocessingWrapper.__iter__(self)
67 def __iter__(self):
---> 68 yield from self.dataloader
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:630, in _BaseDataLoaderIter.__next__(self)
627 if self._sampler_iter is None:
628 # TODO(https://github.com/pytorch/pytorch/issues/76750)
629 self._reset() # type: ignore[call-arg]
--> 630 data = self._next_data()
631 self._num_yielded += 1
632 if self._dataset_kind == _DatasetKind.Iterable and \
633 self._IterableDataset_len_called is not None and \
634 self._num_yielded > self._IterableDataset_len_called:
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:673, in _SingleProcessDataLoaderIter._next_data(self)
671 def _next_data(self):
672 index = self._next_index() # may raise StopIteration
--> 673 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
674 if self._pin_memory:
675 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:42, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)
40 raise StopIteration
41 else:
---> 42 data = next(self.dataset_iter)
43 return self.collate_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:151, in hook_iterator.<locals>.IteratorDecorator.__next__(self)
149 return self._get_next()
150 else: # Decided against using `contextlib.nullcontext` for performance reasons
--> 151 return self._get_next()
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:139, in hook_iterator.<locals>.IteratorDecorator._get_next(self)
137 """Return next with logic related to iterator validity, profiler, and incrementation of samples yielded."""
138 _check_iterator_valid(self.datapipe, self.iterator_id)
--> 139 result = next(self.iterator)
140 if not self.self_and_has_next_method:
141 self.datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:223, in hook_iterator.<locals>.wrap_next(*args, **kwargs)
221 result = next_func(*args, **kwargs)
222 else:
--> 223 result = next_func(*args, **kwargs)
224 datapipe._number_of_samples_yielded += 1
225 return result
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/datapipe.py:383, in _IterDataPipeSerializationWrapper.__next__(self)
381 def __next__(self) -> T_co: # type: ignore[type-var]
382 assert self._datapipe_iter is not None
--> 383 return next(self._datapipe_iter)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
[... skipping similar frames: hook_iterator.<locals>.wrap_generator at line 180 (4 times), MapperIterDataPipe.__iter__ at line 125 (3 times)]
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:126, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
125 for data in self.datapipe:
--> 126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:91, in MapperIterDataPipe._apply_fn(self, data)
89 def _apply_fn(self, data):
90 if self.input_col is None and self.output_col is None:
---> 91 return self.fn(data)
93 if self.input_col is None:
94 res = self.fn(data)
File ~/regression_test/dgl/python/dgl/graphbolt/minibatch_transformer.py:38, in MiniBatchTransformer._transformer(self, minibatch)
37 def _transformer(self, minibatch):
---> 38 minibatch = self.transformer(minibatch)
39 assert isinstance(
40 minibatch, (MiniBatch,)
41 ), "The transformer output should be an instance of MiniBatch"
42 return minibatch
File ~/regression_test/dgl/python/dgl/graphbolt/impl/neighbor_sampler.py:175, in SamplePerLayer._sample_per_layer(self, minibatch)
174 def _sample_per_layer(self, minibatch):
--> 175 subgraph = self.sampler(
176 minibatch._seed_nodes, self.fanout, self.replace, self.prob_name
177 )
178 minibatch.sampled_subgraphs.insert(0, subgraph)
179 return minibatch
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:629, in FusedCSCSamplingGraph.sample_neighbors(self, nodes, fanouts, replace, probs_name)
623 nodes = self._convert_to_homogeneous_nodes(nodes)
625 return_eids = (
626 self.edge_attributes is not None
627 and ORIGINAL_EDGE_ID in self.edge_attributes
628 )
--> 629 C_sampled_subgraph = self._sample_neighbors(
630 nodes,
631 fanouts,
632 replace=replace,
633 probs_name=probs_name,
634 return_eids=return_eids,
635 )
636 return self._convert_to_sampled_subgraph(C_sampled_subgraph)
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:733, in FusedCSCSamplingGraph._sample_neighbors(self, nodes, fanouts, replace, probs_name, return_eids)
689 """Sample neighboring edges of the given nodes and return the induced
690 subgraph.
691
(...)
730 The sampled C subgraph.
731 """
732 # Ensure nodes is 1-D tensor.
--> 733 self._check_sampler_arguments(nodes, fanouts, probs_name)
734 return self._c_csc_graph.sample_neighbors(
735 nodes,
736 fanouts.tolist(),
(...)
740 probs_name,
741 )
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:641, in FusedCSCSamplingGraph._check_sampler_arguments(self, nodes, fanouts, probs_name)
639 if nodes is not None:
640 assert nodes.dim() == 1, "Nodes should be 1-D tensor."
--> 641 assert nodes.dtype == self.indices.dtype, (
642 f"Data type of nodes must be consistent with "
643 f"indices.dtype({self.indices.dtype}), but got {nodes.dtype}."
644 )
645 assert fanouts.dim() == 1, "Fanouts should be 1-D tensor."
646 expected_fanout_len = 1
AssertionError: Data type of nodes must be consistent with indices.dtype(torch.int64), but got torch.int32.
This exception is thrown by __iter__ of SamplePerLayer(datapipe=MiniBatchTransformer, fanout=tensor([4]), prob_name=None, replace=False, sampler=<bound method FusedCSCSamplingGraph.sample_neighbors of FusedCSCSamplingGraph(csc_indptr=tensor([ 0, 289, 290, ..., 1166240, 1166243, 1166243]),
indices=tensor([ 75652, 105878, 59944, ..., 35711, 103121, 30351]),
total_num_nodes=169343, num_edges=1166243,
node_attributes={},
edge_attributes={},)>)
You can get the input node IDs from MFGs.
[6]:
mfgs = data.blocks
input_nodes = mfgs[0].srcdata[dgl.NID]
print(f"Input nodes: {input_nodes}.")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[6], line 1
----> 1 mfgs = data.blocks
2 input_nodes = mfgs[0].srcdata[dgl.NID]
3 print(f"Input nodes: {input_nodes}.")
NameError: name 'data' is not defined
Defining Model
Let’s consider training a 2-layer GraphSAGE with neighbor sampling. The model can be written as follows:
[7]:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import SAGEConv
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type="mean")
self.conv2 = SAGEConv(h_feats, num_classes, aggregator_type="mean")
self.h_feats = h_feats
def forward(self, mfgs, x):
h = self.conv1(mfgs[0], x)
h = F.relu(h)
h = self.conv2(mfgs[1], h)
return h
in_size = feature.size("node", None, "feat")[0]
model = Model(in_size, 64, num_classes).to(device)
Defining Training Loop
The following initializes the model and defines the optimizer.
[8]:
opt = torch.optim.Adam(model.parameters())
When computing the validation score for model selection, usually you can also do neighbor sampling. We can just reuse our create_dataloader function to create two separate dataloaders for training and validation.
[9]:
train_dataloader = create_dataloader(train_set, shuffle=True)
valid_dataloader = create_dataloader(valid_set, shuffle=False)
import sklearn.metrics
The following is a training loop that performs validation every epoch. It also saves the model with the best validation accuracy into a file.
[10]:
from tqdm.auto import tqdm
for epoch in range(10):
model.train()
with tqdm(train_dataloader) as tq:
for step, data in enumerate(tq):
x = data.node_features["feat"]
labels = data.labels
predictions = model(data.blocks, x)
loss = F.cross_entropy(predictions, labels)
opt.zero_grad()
loss.backward()
opt.step()
accuracy = sklearn.metrics.accuracy_score(
labels.cpu().numpy(),
predictions.argmax(1).detach().cpu().numpy(),
)
tq.set_postfix(
{"loss": "%.03f" % loss.item(), "acc": "%.03f" % accuracy},
refresh=False,
)
model.eval()
predictions = []
labels = []
with tqdm(valid_dataloader) as tq, torch.no_grad():
for data in tq:
x = data.node_features["feat"]
labels.append(data.labels.cpu().numpy())
predictions.append(model(data.blocks, x).argmax(1).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
accuracy = sklearn.metrics.accuracy_score(labels, predictions)
print("Epoch {} Validation Accuracy {}".format(epoch, accuracy))
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[10], line 7
4 model.train()
6 with tqdm(train_dataloader) as tq:
----> 7 for step, data in enumerate(tq):
8 x = data.node_features["feat"]
9 labels = data.labels
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/tqdm/notebook.py:250, in tqdm_notebook.__iter__(self)
248 try:
249 it = super().__iter__()
--> 250 for obj in it:
251 # return super(tqdm...) will not catch exception
252 yield obj
253 # NB: except ... [ as ...] breaks IPython async KeyboardInterrupt
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/tqdm/std.py:1181, in tqdm.__iter__(self)
1178 time = self._time
1180 try:
-> 1181 for obj in iterable:
1182 yield obj
1183 # Update and possibly print the progressbar.
1184 # Note: does not call self.update(1) for speed optimisation.
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:630, in _BaseDataLoaderIter.__next__(self)
627 if self._sampler_iter is None:
628 # TODO(https://github.com/pytorch/pytorch/issues/76750)
629 self._reset() # type: ignore[call-arg]
--> 630 data = self._next_data()
631 self._num_yielded += 1
632 if self._dataset_kind == _DatasetKind.Iterable and \
633 self._IterableDataset_len_called is not None and \
634 self._num_yielded > self._IterableDataset_len_called:
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:673, in _SingleProcessDataLoaderIter._next_data(self)
671 def _next_data(self):
672 index = self._next_index() # may raise StopIteration
--> 673 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
674 if self._pin_memory:
675 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:42, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)
40 raise StopIteration
41 else:
---> 42 data = next(self.dataset_iter)
43 return self.collate_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:151, in hook_iterator.<locals>.IteratorDecorator.__next__(self)
149 return self._get_next()
150 else: # Decided against using `contextlib.nullcontext` for performance reasons
--> 151 return self._get_next()
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:139, in hook_iterator.<locals>.IteratorDecorator._get_next(self)
137 """Return next with logic related to iterator validity, profiler, and incrementation of samples yielded."""
138 _check_iterator_valid(self.datapipe, self.iterator_id)
--> 139 result = next(self.iterator)
140 if not self.self_and_has_next_method:
141 self.datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:223, in hook_iterator.<locals>.wrap_next(*args, **kwargs)
221 result = next_func(*args, **kwargs)
222 else:
--> 223 result = next_func(*args, **kwargs)
224 datapipe._number_of_samples_yielded += 1
225 return result
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/datapipe.py:383, in _IterDataPipeSerializationWrapper.__next__(self)
381 def __next__(self) -> T_co: # type: ignore[type-var]
382 assert self._datapipe_iter is not None
--> 383 return next(self._datapipe_iter)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File ~/regression_test/dgl/python/dgl/graphbolt/base.py:263, in EndMarker.__iter__(self)
262 def __iter__(self):
--> 263 yield from self.datapipe
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File ~/regression_test/dgl/python/dgl/graphbolt/dataloader.py:68, in MultiprocessingWrapper.__iter__(self)
67 def __iter__(self):
---> 68 yield from self.dataloader
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:630, in _BaseDataLoaderIter.__next__(self)
627 if self._sampler_iter is None:
628 # TODO(https://github.com/pytorch/pytorch/issues/76750)
629 self._reset() # type: ignore[call-arg]
--> 630 data = self._next_data()
631 self._num_yielded += 1
632 if self._dataset_kind == _DatasetKind.Iterable and \
633 self._IterableDataset_len_called is not None and \
634 self._num_yielded > self._IterableDataset_len_called:
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/dataloader.py:673, in _SingleProcessDataLoaderIter._next_data(self)
671 def _next_data(self):
672 index = self._next_index() # may raise StopIteration
--> 673 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
674 if self._pin_memory:
675 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:42, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)
40 raise StopIteration
41 else:
---> 42 data = next(self.dataset_iter)
43 return self.collate_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:151, in hook_iterator.<locals>.IteratorDecorator.__next__(self)
149 return self._get_next()
150 else: # Decided against using `contextlib.nullcontext` for performance reasons
--> 151 return self._get_next()
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:139, in hook_iterator.<locals>.IteratorDecorator._get_next(self)
137 """Return next with logic related to iterator validity, profiler, and incrementation of samples yielded."""
138 _check_iterator_valid(self.datapipe, self.iterator_id)
--> 139 result = next(self.iterator)
140 if not self.self_and_has_next_method:
141 self.datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:223, in hook_iterator.<locals>.wrap_next(*args, **kwargs)
221 result = next_func(*args, **kwargs)
222 else:
--> 223 result = next_func(*args, **kwargs)
224 datapipe._number_of_samples_yielded += 1
225 return result
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/datapipe.py:383, in _IterDataPipeSerializationWrapper.__next__(self)
381 def __next__(self) -> T_co: # type: ignore[type-var]
382 assert self._datapipe_iter is not None
--> 383 return next(self._datapipe_iter)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
[... skipping similar frames: hook_iterator.<locals>.wrap_generator at line 180 (4 times), MapperIterDataPipe.__iter__ at line 125 (3 times)]
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:125, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
--> 125 for data in self.datapipe:
126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/_hook_iterator.py:180, in hook_iterator.<locals>.wrap_generator(*args, **kwargs)
178 response = gen.send(None)
179 else:
--> 180 response = gen.send(None)
182 while True:
183 datapipe._number_of_samples_yielded += 1
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:126, in MapperIterDataPipe.__iter__(self)
124 def __iter__(self) -> Iterator[T_co]:
125 for data in self.datapipe:
--> 126 yield self._apply_fn(data)
File /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/torch/utils/data/datapipes/iter/callable.py:91, in MapperIterDataPipe._apply_fn(self, data)
89 def _apply_fn(self, data):
90 if self.input_col is None and self.output_col is None:
---> 91 return self.fn(data)
93 if self.input_col is None:
94 res = self.fn(data)
File ~/regression_test/dgl/python/dgl/graphbolt/minibatch_transformer.py:38, in MiniBatchTransformer._transformer(self, minibatch)
37 def _transformer(self, minibatch):
---> 38 minibatch = self.transformer(minibatch)
39 assert isinstance(
40 minibatch, (MiniBatch,)
41 ), "The transformer output should be an instance of MiniBatch"
42 return minibatch
File ~/regression_test/dgl/python/dgl/graphbolt/impl/neighbor_sampler.py:175, in SamplePerLayer._sample_per_layer(self, minibatch)
174 def _sample_per_layer(self, minibatch):
--> 175 subgraph = self.sampler(
176 minibatch._seed_nodes, self.fanout, self.replace, self.prob_name
177 )
178 minibatch.sampled_subgraphs.insert(0, subgraph)
179 return minibatch
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:629, in FusedCSCSamplingGraph.sample_neighbors(self, nodes, fanouts, replace, probs_name)
623 nodes = self._convert_to_homogeneous_nodes(nodes)
625 return_eids = (
626 self.edge_attributes is not None
627 and ORIGINAL_EDGE_ID in self.edge_attributes
628 )
--> 629 C_sampled_subgraph = self._sample_neighbors(
630 nodes,
631 fanouts,
632 replace=replace,
633 probs_name=probs_name,
634 return_eids=return_eids,
635 )
636 return self._convert_to_sampled_subgraph(C_sampled_subgraph)
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:733, in FusedCSCSamplingGraph._sample_neighbors(self, nodes, fanouts, replace, probs_name, return_eids)
689 """Sample neighboring edges of the given nodes and return the induced
690 subgraph.
691
(...)
730 The sampled C subgraph.
731 """
732 # Ensure nodes is 1-D tensor.
--> 733 self._check_sampler_arguments(nodes, fanouts, probs_name)
734 return self._c_csc_graph.sample_neighbors(
735 nodes,
736 fanouts.tolist(),
(...)
740 probs_name,
741 )
File ~/regression_test/dgl/python/dgl/graphbolt/impl/fused_csc_sampling_graph.py:641, in FusedCSCSamplingGraph._check_sampler_arguments(self, nodes, fanouts, probs_name)
639 if nodes is not None:
640 assert nodes.dim() == 1, "Nodes should be 1-D tensor."
--> 641 assert nodes.dtype == self.indices.dtype, (
642 f"Data type of nodes must be consistent with "
643 f"indices.dtype({self.indices.dtype}), but got {nodes.dtype}."
644 )
645 assert fanouts.dim() == 1, "Fanouts should be 1-D tensor."
646 expected_fanout_len = 1
AssertionError: Data type of nodes must be consistent with indices.dtype(torch.int64), but got torch.int32.
This exception is thrown by __iter__ of SamplePerLayer(datapipe=MiniBatchTransformer, fanout=tensor([4]), prob_name=None, replace=False, sampler=<bound method FusedCSCSamplingGraph.sample_neighbors of FusedCSCSamplingGraph(csc_indptr=tensor([ 0, 289, 290, ..., 1166240, 1166243, 1166243]),
indices=tensor([ 75652, 105878, 59944, ..., 35711, 103121, 30351]),
total_num_nodes=169343, num_edges=1166243,
node_attributes={},
edge_attributes={},)>)
Conclusion
In this tutorial, you have learned how to train a multi-layer GraphSAGE with neighbor sampling.